| 相信有些小伙伴已經(jīng)隱隱約約有聽(tīng)說(shuō)過(guò)UDI和UMI這兩個(gè)英文縮寫(xiě),但是一直沒(méi)搞清楚它們?nèi)巧叮克鼈兡芨缮叮?/span> |
| 在正文開(kāi)始前,我們先來(lái)“揭秘”UDI和UMI的全稱(chēng): UDI的全稱(chēng)為Unique Dual Index,譯為雙端標(biāo)簽技術(shù)。 UMI的全稱(chēng)為Unique Molecular Identifier,譯為分子條形碼或者分子標(biāo)簽技術(shù)。 別急,要弄清這兩個(gè)概念,還得從二代測(cè)序的那些事情說(shuō)起: 我們都知道二代測(cè)序技術(shù)是近十年來(lái)曝光率非常高、非常受關(guān)注的基因組分析技術(shù)。以Illumina為代表的測(cè)序儀廠(chǎng)商不斷推出更新型號(hào)的測(cè)序儀,不斷刷新測(cè)序通量,但不變的仍是多樣本混合后測(cè)序的策略。 要實(shí)現(xiàn)對(duì)多個(gè)樣本同時(shí)測(cè)序,必須在各樣本PCR擴(kuò)增階段,往DNA片段上添加一段分子序列作為樣本標(biāo)簽,這種標(biāo)簽叫做index。 |
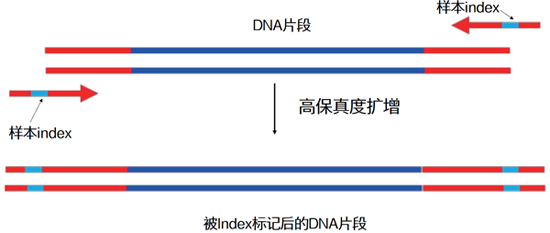 |
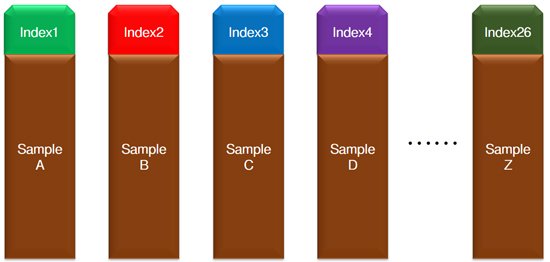
| 這樣,每個(gè)樣本就帶上屬于它的“專(zhuān)屬號(hào)碼牌”,在多樣本混合測(cè)序后,生信工程師能通過(guò)“翻牌”,確定這個(gè)“號(hào)碼”所代表的就是“尋尋覓覓”的那個(gè)“它”。 |
 |
| Index一般由8位堿基所組成,常有單端與雙端兩種添加模式,為了增加同時(shí)上樣的通量,大家一般在面臨大量樣本同時(shí)測(cè)序時(shí),會(huì)選擇雙端index↓ |
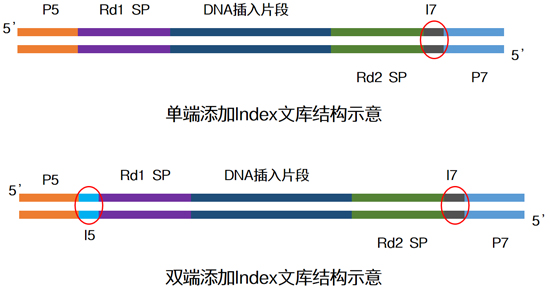 |
| 目前常用的雙端index策略是通過(guò)少數(shù)幾種index序列排列組合,去實(shí)現(xiàn)更多樣本的標(biāo)簽區(qū)分(如96種),但這種方式一直存在交叉污染的可能。 |
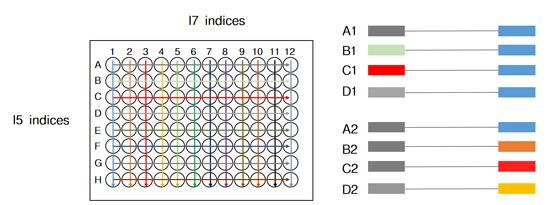 |
| 同時(shí),為了進(jìn)一步提升通量與擴(kuò)增效率,降低測(cè)序成本,Illumina為Novaseq等高通量型測(cè)序儀引入了圖案化流動(dòng)槽(Patterned Flow Cell Technology,PFCT)和排他性擴(kuò)增(Exclusion Amplification,ExAmp)成簇技術(shù)。這兩個(gè)看似美好的技術(shù)卻無(wú)意間放大了一種叫做標(biāo)簽跳躍(index hopping)的樣本標(biāo)簽錯(cuò)配的現(xiàn)象,導(dǎo)致科研人員無(wú)法正確拆析樣本與數(shù)據(jù)的關(guān)系,終可能與重大發(fā)現(xiàn)“失之交臂”。 |
| 為了降低標(biāo)簽跳躍,Illumina在白皮書(shū)[1]中提到可以使用UDI雙端特殊標(biāo)簽對(duì)樣本進(jìn)行標(biāo)記,混樣后進(jìn)行測(cè)序。 |
| UDI的引入使得文庫(kù)兩端的index序列是一對(duì)一組合的,不存在共用。換句話(huà)說(shuō),只有兩端帶有*正確index序列的reads才能進(jìn)入后續(xù)的樣本分析,從而可以剔除標(biāo)簽錯(cuò)配的reads,有效避免樣本之間的數(shù)據(jù)串?dāng)_。 |
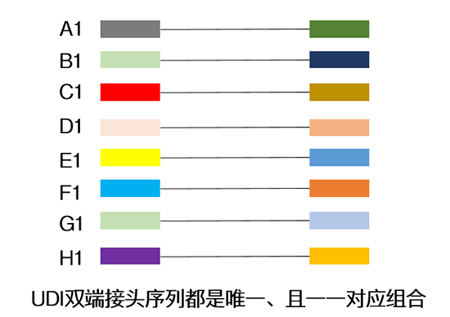 |
| 一句話(huà)總結(jié):采用UDI策略,能更正確拆解測(cè)序數(shù)據(jù)與樣本之間的一一對(duì)應(yīng)關(guān)系,減小樣本“戴錯(cuò)號(hào)碼牌”的概率。 |
| 下面再來(lái)講講名為分子標(biāo)簽技術(shù)的UMI: |
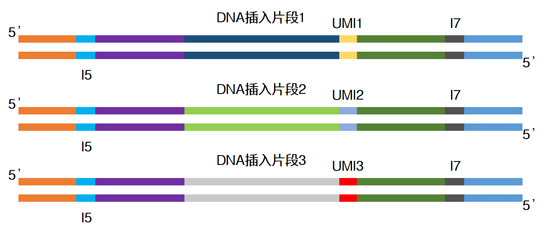
| UMI的原理就是給每一條原始DNA片段加上一段*的標(biāo)簽序列,經(jīng)PCR擴(kuò)增后一起進(jìn)行測(cè)序。這樣根據(jù)不同的標(biāo)簽序列,生信人員就能區(qū)分不同來(lái)源的DNA模板,分辨哪些是PCR擴(kuò)增及測(cè)序過(guò)程中的隨機(jī)錯(cuò)誤造成的假陽(yáng)性突變,哪些是患者真正攜帶的突變,從而提高檢測(cè)靈敏度和特異性。 |
 |
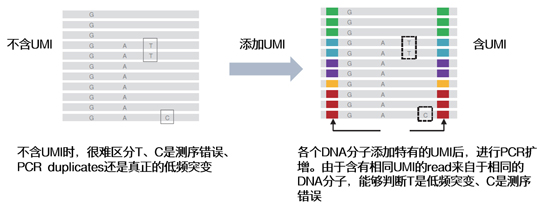 |
| 一些需要較高正確度的應(yīng)用,如腫瘤稀有突變分析,常會(huì)對(duì)5%、甚至1%左右的稀有變異作檢測(cè)。這時(shí)一旦出現(xiàn)測(cè)序錯(cuò)誤、或者PCR偏差,便會(huì)產(chǎn)生大量假陽(yáng)性結(jié)果,因此需要添加UMI進(jìn)行校正。 |
| 一句話(huà)總結(jié):做稀有突變檢測(cè)、校正測(cè)序錯(cuò)誤與PCR偏差,UMI“勞苦功高”。 |
| 看到這里,關(guān)于UDI和UMI的介紹已基本完成。 |
| 接下來(lái)我們來(lái)看一個(gè)實(shí)際案例應(yīng)用。 |
| 我們了解到這位客戶(hù) ① 近正在研發(fā)腫瘤稀有突變分析的項(xiàng)目; ② 樣本類(lèi)型主要是FFPE(石蠟包埋樣本)、cfDNA(游離DNA); ③ 起始量大概在幾十ng;④準(zhǔn)備自己建庫(kù),然后送樣測(cè)序,平臺(tái)是Novaseq; ⑤ 由于是剛接觸建庫(kù)實(shí)驗(yàn),不希望操作太復(fù)雜。 我思考了大概1秒鐘,就從我們豐富的DNA-Seq文庫(kù)構(gòu)建產(chǎn)品線(xiàn)中找到了一款合適的產(chǎn)品↓ |
| ThruPLEX Tag-Seq HV |
| 為什么說(shuō)這款產(chǎn)品合適呢?我們來(lái)對(duì)標(biāo)這位客戶(hù)的幾個(gè)需求。 |
| 需求1:希望操作簡(jiǎn)便,不要太繁瑣 |
| 對(duì)標(biāo)1:ThruPLEX Tag-Seq HV這款試劑盒支持單管、三步操作,手動(dòng)15 min,全程2 h,無(wú)需在建庫(kù)過(guò)程中轉(zhuǎn)管或純化。 |
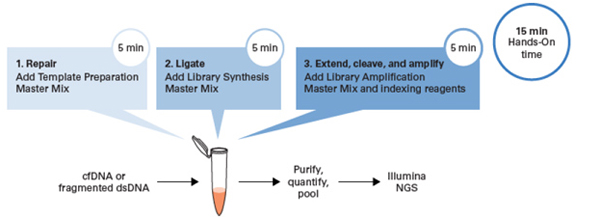 |
| 我們比較了ThruPLEX HV和K、N兩家公司的試劑盒,只有ThruPLEX是單管操作、時(shí)間短的系統(tǒng)。 |
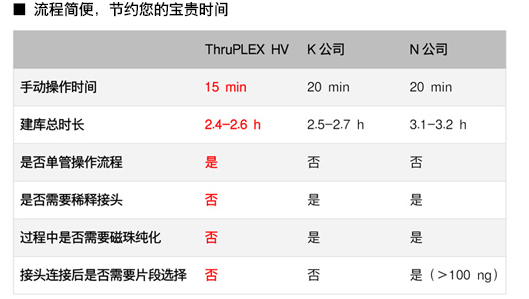 |
| 所以,無(wú)論新手還是老手,都能很快上手! |
| 需求2:樣本類(lèi)型為FFPE DNA、cfDNA,起始量大概在幾十ng |
| 對(duì)標(biāo)2:ThruPLEX Tag-Seq HV支持5-200 ng FFPE DNA、cfDNA起始,input volume為30μl,無(wú)需樣品濃縮。 |
| 需求3:Novaseq測(cè)序分析稀有變異 |
| 對(duì)標(biāo)3:ThruPLEX Tag-Seq HV搭配UDI建庫(kù),可以有效降低index hopping效應(yīng),是高通量型Illumina測(cè)序儀的“友好伙伴” |
| ThruPLEX Tag-Seq HV莖環(huán)形接頭上還包含7位堿基的固定型UMI,雙端總共可有144種UMI連接到DNA分子兩端,以識(shí)別一致序列,減少擴(kuò)增或者測(cè)序錯(cuò)誤帶來(lái)的假陽(yáng)性突變。 |
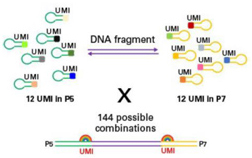 |
| 再舉幾個(gè)例子 |
| Takara科學(xué)家采用ThruPLEX Tag-Seq HV對(duì)10 ng起始的Quan-Plex Patient-Like ctDNA標(biāo)準(zhǔn)品(AccuRef)構(gòu)建文庫(kù),腫瘤相關(guān)的基因采用IDT xGEN Pan Cancer Panel進(jìn)行捕獲富集,隨后用UMIs鑒定了ctDNA標(biāo)準(zhǔn)品中特定位點(diǎn)的實(shí)際突變頻率。結(jié)果顯示,檢測(cè)到的突變頻率分別與預(yù)期1%、5%的等位突變頻率接近,而陰性對(duì)照組沒(méi)有在位點(diǎn)處檢測(cè)到任何突變。 |
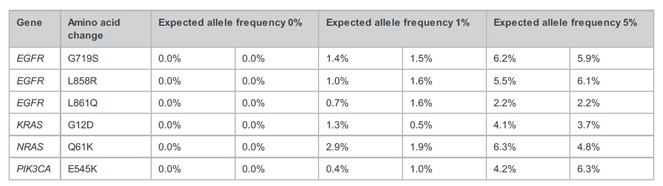 |
| 同時(shí),為了比較UMI與常規(guī)使用的坐標(biāo)法之間的效果差異,Takara科學(xué)家先使用未去重或者僅用坐標(biāo)法去重的文件分析,在預(yù)期的EGFR L858R突變附近觀察到大量的低頻及隨機(jī)等位基因頻率突變。而隨后用UMI校正、過(guò)濾數(shù)據(jù)后,清除了假陽(yáng)性突變,得到了預(yù)期的突變分析結(jié)果! |
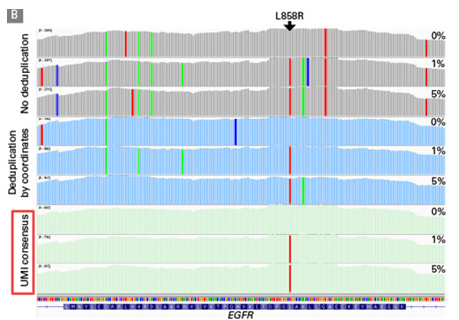 |
| 經(jīng)過(guò)幾場(chǎng)對(duì)標(biāo),我們明確了ThruPLEX Tag-Seq HV能滿(mǎn)足那位客戶(hù)開(kāi)發(fā)cfDNA/FFPE DNA稀有突變項(xiàng)目的需求。 |
| 當(dāng)然,若小伙伴們也有同等需求,ThruPLEX Tag-Seq HV定能不負(fù)所望。 |
| 參考文獻(xiàn): |
| [1] Illumina.Effects of index misassignment on multiplexing and downstream Analysis(white paper). 4(2017). |
(空格分隔,最多3個(gè),單個(gè)標(biāo)簽最多10個(gè)字符)

員.png) 5
5
立即詢(xún)價(jià)
您提交后,專(zhuān)屬客服將第一時(shí)間為您服務(wù)